Today I’m going to give you another tip, but now focusing on Scalar Functions vs Table-Valued Functions.
Many developers love to use Scalar Functions inside of SQL Server because it lets them easily reuse code, which is a common goal in object-oriented programming.
Why would you ever write the same piece of logic more than once after all?
But the problem with Scalar Functions is that the query optimizer performs row-by-row processing instead of set-based logic.
Scalar Functions are known as “silent performance killer“, because even if we use some of the techniques in our benchmark toolkit, like looking at SET Statistics IO, and execution plans, we wouldn’t be able to see the row-by-row processing.
Let’s take a look at a sample query using Scalar Function:
CREATE FUNCTION GetmaxProductQty_Scalar (@ProductId INT)
returns INT
AS
BEGIN
DECLARE @maxQty INT
SELECT @maxQty = Max(sod.orderqty)
FROM Sales.SalesOrderDetail sod
WHERE sod.productid = @ProductId
RETURN ( @maxQty )
END
Here’s a query that uses the new function. It does nothing more than getting the max quantity sold for each product in the Production.Product table.
SELECT productid,
dbo.GetMaxProductqty_scalar(productid) m
FROM Production.Product
ORDER BY productid
If we look at the SET Statistics IO, you might think this is great query just because we only have 15 logical reads. But does that mean that we don’t have anything else to improve here?

Keep in mind that this is just the Product’s table, and our function is referencing SalesOrderDetail. That is the reason why this is a “silent performance killer”.
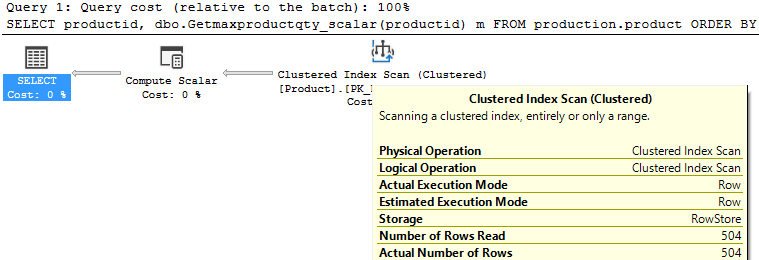
If we check the execution plan, there is only an Index Scan from Product’s table.
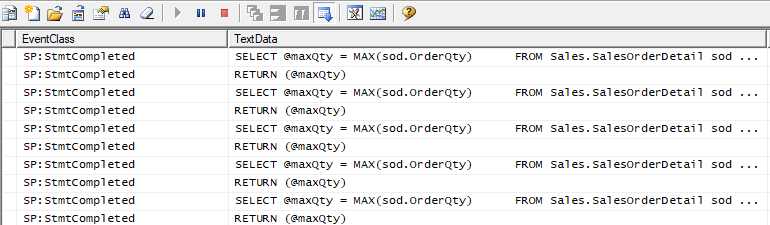
However, using SQL Server Profiler, we are able to see the row-by-row processing:
Now, let’s create the Table-Valued Function, doing exactly the same thing on SalesOrderDetail.
You will notice that there is a slight difference compared to the previous function GetMaxProductQty_Scalar.
CREATE FUNCTION GetMaxProductQty_inline (@ProductId INT)
returns TABLE
AS
RETURN
(SELECT Max(sod.orderqty) AS maxqty
FROM sales.SalesOrderdetail sod
WHERE sod.productid = @ProductId)
You can check the following examples using the new function:
SELECT productid,
maxqty
FROM production.product
CROSS apply dbo.GetMaxProductqty_Inline(productid) MaxQTy
ORDER BY productid
SELECT productid,
( SELECT maxqty
FROM dbo.GetMaxProductqty_Inline(productid)) MaxQty
FROM production.product
ORDER BY productid
If we now look at the SET Statistics IO, we can see the information from SalesOrderDetail:

The other thing to notice is that our execution plan has changed, and now includes everything. We can see the index scan on SalesOrderDetail, so we still may have some opportunities for improvement.
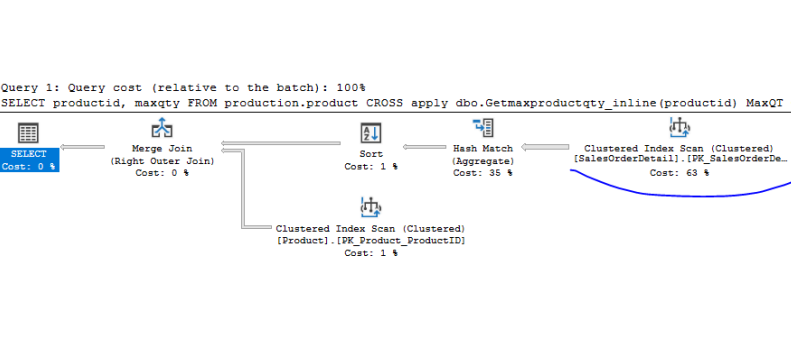
The main point here is that our silent performance killer is gone, and we don’t see the row-by-row processing anymore. So, if you have the opportunity to push that over to a Table Function, it will allow you to use set-based logic, which gives you much faster execution times.